




Оценка алгоритмов для самых маленьких
 24.06.2018
24.06.2018 7 мин
7 мин
Мой испытательный срок на новой работе подходит к концу, быстро время пролетело. У нас в компании принято рассказывать небольшой доклад по такому случаю. А так как я совсем недавно закончил курс Алгоритмы и структуры данных в ШАД, я решил почему бы не сделать доклад именно на эту тему. И конечно, почему бы не написать об этом!
Аудитория
Статья подойдет абсолютно всем, но заинтересует лишь тех кто совсем не знаком с алгоритмами и структурами данных или недавно начал изучать язык программирования — Swift.
Краткое описание
Это скорее обзорная статья, которая поможет вам слегка заглянуть в мир алгоритмов и структур. В начале я расскажу немного о теории оценки алгоритмов, затем немного практики. И в самом конце статьи немного о практическом применении всего этого или зачем это всё нужно?
Оценка алгоритмов

Когда речь заходит об алгоритмах, встает вопрос об оценке их эффективности. Причем интересна оценка, которая не зависит от конфигурации конкретного устройства. Не важно на сколько быстрый у вас ноутбук или телефон, оценивается характер роста параметров алгоритма.
А что за параметры? Время и память. Причем именно дополнительная память, так как обычно размер входных данных не учитывается при оценке. Очень часто приходится жертвовать одним в пользу другого и такие ситуации называют trade-off.
Итак, такую оценку принято производить с помощью асимптотического анализа, в котором эффективность оценивается в зависимости от размера входных данных. Для этого используется математическое обозначение Big O Notation.
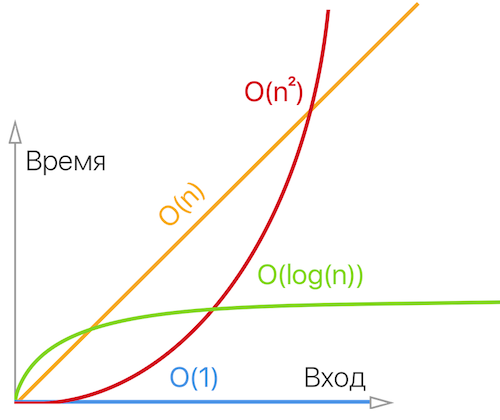
Выше на графике я постарался изобразить основные оценки:
- O(1) константная сложность;
- O(log(n)) логарифмическая сложность;
- O(n) линейная сложность;
- O(n²) квадратичная сложность.
Также важно упомянуть об учетной или амортизированной оценке. Она применяется, когда невозможно или просто не выгодно оценивать стоимость операций одной оценкой. Стоимость может меняться от определенных условий, но иногда можно взять усредненную оценку по всем операциям. Такая оценка и будет называться учетной.
Это самый минимум теории по оценке и чуть ниже я покажу как это используется на практике.
Структуры данных
Сразу хочу заметить, что Swift не богат на различные структуры данных. Их всего три: Array, Dictionary и Set. Все эти коллекции являются структурами struct, а в Swift все структуры являются Value Type. Это означает, что они передаются по значению, то есть копируются.
Для простоты я решил рассмотреть только массив, и этого будет достаточно для первого раза.
Array (Массив)
Array — упорядоченная коллекций с произвольным доступом к элементам. Также, в других языках программирования, такую структуру называют вектором. Наверное, это самая популярная структура.
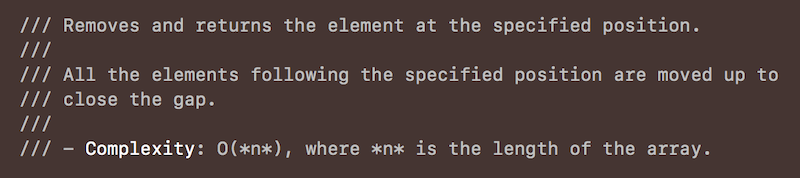
Рассмотрим базовые операции: доступ к конкретному элементу (subscript), добавление нового элемента в конец (append) и удаление/добавление элемента (remove / insert). Ниже я приведу сокращенные комментарии прямо из исходного кода.
Subscript
Доступ к элементу работает за O(1), но запись может вызвать операцию копирования всей коллекции и привести к сложности O(n).

Может у вас возник вопрос, а почему это запись вызывает копирование всего массива? Как я уже упомянул выше, массивы всегда передаются по значению или копируются. Но чтобы оптимизировать этот процесс в Swift есть механизм COW (Copy-on-write).

И что же получается? Дело в том, что когда мы передаем массив в функцию или присваиваем в новую переменную он не копируется. Но если мы начинаем его изменять, то возможно две ситуации:
- Массив никуда не передавали и на него ссылается лишь одна переменная, тогда мы записываем по индексу за O(1). Нет необходимости копировать весь массив;
- Иначе, доступ к массиву осуществляется из нескольких мест. Тогда нам придется создать его копию и затем изменить именно её. Для всех остальных заинтересованных массив остается неизменным. Такая операция будет оцениваться как O(n).
Append
Добавление элемента в конец работает за учетную стоимость O(1). Почему учетную? Потому что если вся память выделенная под массив потрачена, то необходимо выделить новую память большего размера и затем перенести всю коллекцию на новое место, что приведет к сложности O(n). Но, существуют специальные стратегии выделения памяти с запасом, которые гарантируют, что количество таких операций выделения памяти будет незначительным по сравнению с вставками в ранее выделенное место. Тогда получается что большинство операций будет выполняться за O(1), но иногда придется копировать коллекцию за O(n).

Insert/Remove
Операция добавления элемента работает за O(n), так как при вставке потребуется сдвинуть каждый элемент после позиции вставки.

Операция удаления работает за O(n), так как потребуется сдвинуть все элементы после позиции удаляемого элемента.
Однажды я проходил собеседование и мне нужно было написать алгоритм, который удалит все нули из массива за O(n). И первое решение, которое пришло мне в голову было — написать while и воспользоваться операцией remove. Я думал вся хитрость в том, чтобы обойти for in. Такой алгоритм оценивался в O(n²).

Я постарался написать обо всём очень кратко, поэтому если у вас остались вопросы, то смело задавайте их в комментариях.
И зачем мне всё это?!
Пока я учился мне часто задавали этот вопрос. Давайте попробуем разобраться:

- Собеседования. Да да, крупные компании очень любят давать простые задачи на эту тему. А в некоторых непростые. Или даже не задачи, а просто задавать вопросы приводящие к дискуссии. Как работает хеш функция? Какие худшие входные данные для быстрой сортировки и как её улучшить? Как искать минимальный элемент в массиве за константное время? А вы хотите работать в интересном для вас месте? Тогда будьте готовы, возможно вас это коснётся;
- Развитие. Я считаю каждый уважающий себя программист должен развиваться в области компьютерных наук. Иначе вам просто сложнее будет разбираться в деталях реализации, рассуждать на общие темы и писать что-то своё. Программирование это не только знание синтаксиса языка и стандартных библиотек. Это также алгоритмы и структуры данных, архитектура, различные утилиты, понимание как всё это устроенно на более низком уровне. Я сам долгое время старался избегать всего этого. И очень удивился, когда узнал что в одной крупной компании не важен опыт работы на конкретном языке. Они считают, что это может освоить любой студент за 3 месяца работы в команде. Важна база.
Я не стал делать это третьим пунктом, но лично мне нравится решать различные сложные задачи. Мне нравится ощущение того, что я сделал что-то сложное (почти невозможное для себя). Но, чтобы решать сложные задачи, нужно не бояться браться за то, что кажется нереально трудным для вас. Иначе как научиться? Про это я уже писал в статье про ШАД, иногда нужно трайхардить)
Выводы
А выводы делайте сами, нужно это вам или нет? Вы можете присоединиться к обсуждению статьи на форуме.
В ближайшее время я планирую решать различные алгоритмические задачи и готовиться к Яндекс.Блиц 2018. Не ради собеседования, а ради интереса) Я не так давно окончил курс в ШАД и мне хотелось бы применить свои знания в бою. Это не реклама! Так уж получается, что у Яндекса очень интересные события) Я работаю в другом месте.
На сколько мне известно, многие мобильные разработчики валятся на собеседованиях именно на математических или алгоритмических задачах. Но, этот навык можно покачать с помощью решения задач в различных сервисах.
Спустя какое-то время...
К сожалению, времени на организацию совместной подготовки не было, так как я стал преподавать курс по iOS разработке в Тинькофф Финтех школе. Да и на личную подготовку тоже) Но мне удалось взять третье место в Яндекс.Блиц 2018 по Мобильной разработке. Отборочный этап проходил на Swift, финал на C++. Попал в призы благодаря алгоритму Ахо-Корасик.

Всем спасибо за внимание! На этом всё! Ещё увидимся! но это не точно.